修正日: 07/10/24
Shark
Performance Tools入門 その4
1. はじめに
Sharkは対象アプリケーションの実行状態を調べ、実行速度などの最適化の可能性を調べるためのツールです。同様のツールとしてSamplerというアプリケーションがありますが、Sharkはソースコードレベルで負荷の大小を調べることができるなどより強力な(かつ複雑な)機能を持ち、使いこなすことができればとても有用なソフトです。本稿ではver4.2.2を元に説明します。なおこのソフトはDeveloper Toolsをインストールする際、Computer Hardware Understanding Developer (CHUD) toolをチェックすることでインストールされます(デフォルトの状態では入らないようです)。しかしWeb上から単独でダウンロードすることも可能ですので、ADCのサイト内を探してみてください(今のところ「Download」の「Developer Tools」のページにあります)。
2. 簡単な使い方
まずはNobleApeというソフトを使って一般的な操作手順を説明します。IntelCPUへの以降が進む今となっては古い情報も多いですが、基本的な概念は同じです。まずはNobleApeを準備します。「/Developer/Examples/CHUD」というフォルダ内に「NobleApe」というフォルダがありますので、ビルドして起動してみてください(ビルド構成は「Development」)。
【図1】 NobleApe

このアプリは無人島にすむ猿のシミュレーターだそうです(図1)。Mapが島の全体図と猿の位置、Terrainが選択中の猿のいる地形、Brainが選択中の猿の脳をシミュレートしています。もちろん猿か犬かはどうでもいい事で、Brainウィンドウの「APE THOUGHTS PER SEC : 」の値にだけ注目してください。この値がベンチマークの数字で、大きいほど効率的に(速く)動いていることになります。
【図2】 SharkでProcessを選択する

次にSharkを起動します。一番右「Everything」になっているポップアップメニューで「Process」を選択し、右のポップアップからNobleApeのプロセスを選択します(図2)(NobleApeはデバッグシンボルを含んだ状態、Dvelopmentのビルド状態で起動してください)。「Start」ボタンを押すとサンプリングが始まり、30秒経つと自動的に終了、サンプリング結果が表示されます(図3)。
【図3】 サンプリング結果
まず一番下の「Thread」ポップアップメニューに注目してください。G5DualやIntelCoreDuoなどマルチ(コア)プロセッサ環境をお使いの場合、NobleApeのCPU使用率は50%程度で、mach_kernelが残り半分を消費している可能性があります。これはつまりCPUの待ち時間が全体の半分近くを消費しているということで、NobleApeをマルチスレッド化してCPU使用率を上げることで最適化できることがわかります。
NobleApeの「Benchmark」メニューの「Threaded」を選択してみてください。内部処理がマルチスレッド化されて実行されます。マルチプロセッサ環境では猿の動きが速くなり、ベンチマークの値が跳ね上がるはずです。逆にシングルプロセッサ環境ではほとんど効果がないか、むしろ遅くなります。シングルスレッドでCPUを100%消費しているのに、スレッドの切替などで無駄なコストがかかってしまうためです。
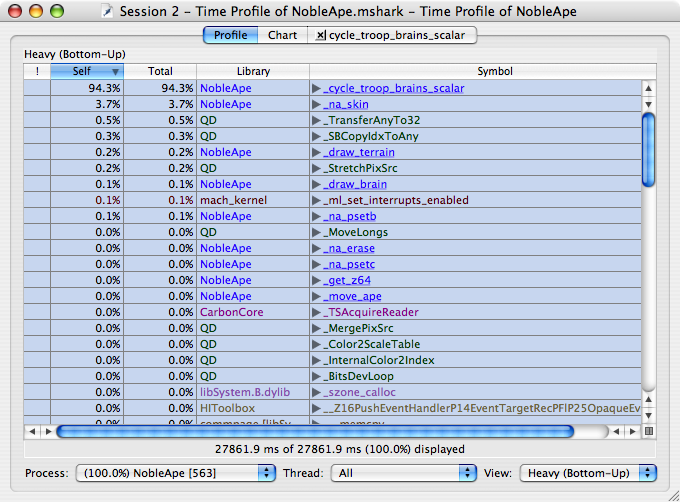
次にウィンドウ中央の表に注目します。初期状態では内部処理の中で多くの時間を費やした順に関数名が並びます。図4の「Self」の値に注目してください。
【図4】 負荷の大きい関数のリスト
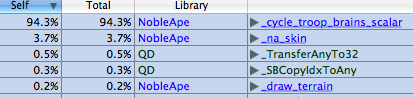
NobleApe内の処理時間の実に94.3%が「cycle_troop_brains_scalar」という関数の中で費やされていることが分かります。つまりこの関数を最適化すると、大きな速度向上が期待できるという事です。逆に二番目以降の関数をいくら最適化しても実効速度にはほとんど影響が無いという事でもあります。闇雲にソースコードをいじりまわすより、最も重い関数をピンポイントで改善することで、非常に効率的な作業をすることができます。
ターゲットとなる関数が決まったら、その関数をダブルクリックします。今度はソースコード一行ごとの負荷を見ることができます(図5)。ただしソースを表示できるのはデバッグシンボルを持つ関数だけです。
【図5】 コードビュー
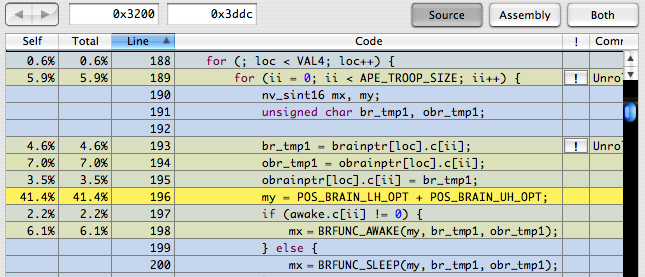
196行目一行が処理時間の半分近くを費やしていることが分かります。さらに188行目から214行目までのforループの行をまとめて選択してください。下部に選択中の行の合計が表示されます(図6)。
【図6】forループの合計

このforループだけで93.4%の時間を費やしています。つまりこのたった27行を最適化する事でアプリケーション全体の速度向上を達成できるという事です(ちなみにソースコード横の「!」ボタンでCPUごとの最適化のヒントを表示できます)。NobleApeの「Benchmark」メニューの「Vector」を選択してみてください。「cycle_troop_brains_scalar」の代わりにAltiVec(IntelMacではSSE2)に最適化された「cycle_troop_brains_vector」が実行されます。G4、G5、Intel環境ではかなり速度が上がるはずです。
以上がSharkのごく基本的な使い方です。以下のページではSharkの各機能について(全てではありませんが)もう少し細かく説明していきます。